 网络科学研究速递
网络科学研究速递
- 具有边相关顶点权重的超图:p-拉普拉斯算子和谱聚类;
- 通过 Tiny Networks 训练的神经模型拆解复杂网络;
- 通过阈值优化从多个子任务中做出可靠决策:野外内容审核;
- 通过社交媒体的词汇分析绘制的美国文化区域;
- 延迟 SEIRDS 流行病模型的数学分析:确定性和随机方法;
- Caputo 意义上的新分数模型,用于研究法国 COVID-19 传播的动态;
- 当前 COVID-19 Omicron 浪潮期间有关在线学习的 Twitter Chatter 大规模数据集;
- 不断扩大的宇宙文明中交流的因果限制;
具有边相关顶点权重的超图:p-拉普拉斯算子和谱聚类
原文标题: Hypergraphs with Edge-Dependent Vertex Weights: p-Laplacians and Spectral Clustering
地址: http://arxiv.org/abs/2208.07457
作者: Yu Zhu, Santiago Segarra

摘要: 我们研究了最近提出的超图模型的 p-拉普拉斯算子和谱聚类,该模型结合了边相关的顶点权重 (EDVW)。这些权重可以反映超边内顶点的不同重要性,从而赋予超图模型更高的表达性和灵活性。通过构建基于子模 EDVWs 的分裂函数,我们将具有 EDVWs 的超图转换为谱理论得到更好发展的子模超图。这样,在子模超图设置下提出的 p-Laplacian 和 Cheeger 不等式等现有概念和定理可以直接扩展到具有 EDVW 的超图。对于具有基于 EDVWs 的分裂函数的子模超图,我们提出了一种有效的算法来计算与超图 1-拉普拉斯算子的第二小的特征值相关的特征向量。然后我们利用这个特征向量对顶点进行聚类,实现了比基于 2-拉普拉斯算子的传统谱聚类更高的聚类精度。更广泛地说,所提出的算法适用于所有图可约化的子模超图。使用真实世界数据的数值实验证明了结合基于 1-拉普拉斯算子和 EDVW 的谱聚类的有效性。
通过 Tiny Networks 训练的神经模型拆解复杂网络
原文标题: Dismantling Complex Networks by a Neural Model Trained from Tiny Networks
地址: http://arxiv.org/abs/2208.07792
作者: Jiazheng Zhang, Bang Wang

摘要: 我们能否使用一种神经模型来有效地拆除许多复杂但独特的网络?这篇文章给出了肯定的答案。不同的现实世界系统可以抽象为复杂的网络,每个网络都由许多功能节点和边组成。渗透理论表明,仅删除少数几个重要节点会导致整个网络崩溃。然而,由于其 NP 难度,找到最少数量的此类重要节点对于大型网络来说是一项相当具有挑战性的任务。以前的研究已经提出了许多中心性度量和启发式算法来解决这个网络拆除(ND)问题。与他们的不同,本文试图通过设计一个可以从微型合成网络训练但将应用于各种现实世界网络的神经模型来处理 ND 任务。乍一看,这似乎是一个令人沮丧的任务,因为网络规模和拓扑在不同的现实世界网络中完全不同。尽管如此,本文还是对设计和训练神经影响排名模型 (NIRM) 进行了富有洞察力的努力。与最先进的竞争对手相比,十五个真实世界网络的实验验证了它的有效性,因为它主要需要更少的重要节点来拆除网络。其成功的关键在于,除了我们在训练数据集构建中的创新标记方法外,我们的 NIRM 还可以有效地编码用于排名节点的局部结构和全局拓扑信号。
通过阈值优化从多个子任务中做出可靠决策:野外内容审核
原文标题: Reliable Decision from Multiple Subtasks through Threshold Optimization: Content Moderation in the Wild
地址: http://arxiv.org/abs/2208.07522
作者: Donghyun Son, Byounggyu Lew, Kwanghee Choi, Yongsu Baek, Seungwoo Choi, Beomjun Shin, Sungjoo Ha, Buru Chang

摘要: 社交媒体平台努力通过内容审核来保护用户免受有害内容的侵害。这些平台最近利用机器学习模型来处理每天大量用户生成的内容。由于审核政策因国家和产品类型而异,因此通常根据政策训练和部署模型。然而,这种方法效率非常低,尤其是当政策发生变化时,需要对数据集重新标记和模型重新训练转移的数据分布。为了缓解这种成本低效,社交媒体平台通常采用第三方内容审核服务,提供多个子任务的预测分数,例如预测未成年人员、粗鲁手势或武器的存在,而不是直接提供最终的审核决策。然而,根据特定目标策略的多个子任务的预测分数做出可靠的自动调节决策尚未得到广泛探索。在这项研究中,我们制定了内容审核的真实场景,并引入了一种简单而有效的阈值优化方法,该方法可以搜索多个子任务的最佳阈值,从而以具有成本效益的方式做出可靠的审核决策。大量实验表明,与现有的阈值优化方法和启发式方法相比,我们的方法在内容审核方面表现出更好的性能。
通过社交媒体的词汇分析绘制的美国文化区域
原文标题: American cultural regions mapped through the lexical analysis of social media
地址: http://arxiv.org/abs/2208.07649
作者: Thomas Louf, Bruno Gonçalves, Jose J. Ramasco, David Sanchez, Jack Grieve

摘要: 文化领域代表了一个有用的概念,它融合了社会科学的不同领域。理解人类如何在社会中组织和关联他们的想法和行为有助于理解他们对不同问题的行为和态度。然而,塑造一个文化区域的共同特征的选择有些武断。所需要的是一种可以利用大量在线数据(尤其是通过社交媒体)来识别文化区域而没有临时假设、偏见或偏见的方法。在这项工作中,我们通过引入一种基于对微博帖子中的大型数据集的自动分析来推断文化区域的方法,朝着这个方向迈出了关键的一步。我们的方法基于这样一个原则,即文化归属可以从人们之间讨论的话题中推断出来。具体来说,我们测量了美国社交媒体中产生的书面话语的区域差异。从地理标记推文中内容词的频率分布中,我们找到了词的使用区域热点,并从中推导出区域变化的主要成分。通过在这个低维空间中对数据进行层次聚类,我们的方法产生了清晰的文化区域和定义它们的讨论主题。我们获得了明显的南北分离,这主要受非裔美国人文化的影响,以及进一步的连续(东西)和非连续(城乡)划分,提供了当今美国文化区域的全面图景。
延迟 SEIRDS 流行病模型的数学分析:确定性和随机方法
原文标题: Mathematical analysis of a delayed SEIRDS epidemics models: deterministic and stochastic approach
地址: http://arxiv.org/abs/2208.07690
作者: Mohamed Ben Alaya, Walid Ben Aribi, Slimane Ben Miled

摘要: 本研究的主要目标是调查延迟对易感-暴露-感染-恢复-死亡和易感 (SEIRDS) 模型动态的影响,我们在其中添加了一个随机项来解释 COVID-19 参数的不确定性估计。我们运行两种模型,一种是确定性的,一种是随机的,并表明它们的解决方案存在并且是独一无二的。我们还用数值方法研究了免疫丧失对新一波出现时间的影响,以及疾病灭绝和持续存在的必要条件。
Caputo 意义上的新分数模型,用于研究法国 COVID-19 传播的动态
原文标题: A new fractional model in Caputo sense for studying the dynamics of COVID-19 spread in France
地址: http://arxiv.org/abs/2208.07717
作者: Mahmoud H. A. Saleh, Tarek M. Abed-Elhameed

摘要: COVID-19 大流行已在世界范围内迅速蔓延,并给几乎所有涉及法国的国家的公共卫生带来了负担。在 SARS-CoV-2 传播后,法国总共造成了许多人死亡。在本文中,我们开发了具有整数和分数阶的模型,以研究法国医院和重症监护病房 (ICU) 中 COVID-19 传播的动态。此外,本文旨在利用可用的实际数据,探讨预防措施对整个法国医院和重症监护室 COVID-19 感染病例总数的影响。
当前 COVID-19 Omicron 浪潮期间有关在线学习的 Twitter Chatter 大规模数据集
原文标题: A Large-Scale Dataset of Twitter Chatter about Online Learning during the Current COVID-19 Omicron Wave
地址: http://arxiv.org/abs/2208.07810
作者: Nirmalya Thakur

摘要: 据报道,COVID-19 Omicron 变体是 COVID-19 免疫逃避性最强的变体,导致全球 COVID-19 病例激增。这导致世界不同地区的学校、学院和大学过渡到在线学习。因此,Twitter 等社交媒体平台以推文的形式看到与在线学习相关的对话有所增加。挖掘此类推文以开发数据集可以作为不同应用程序和用例的数据资源,这些应用程序和用例与当前 COVID-19 病例激增期间在线学习的兴趣、观点、意见、观点、态度和反馈分析相关由 Omicron 变体。因此,这项工作展示了自 2021 年 11 月首次检测到 COVID-19 Omicron 变体病例以来,来自世界不同地区的在线学习对话的大规模开放访问 Twitter 数据集。该数据集符合隐私政策,开发者协议和 Twitter 内容再分发指南,以及科学数据管理的 FAIR 原则(可查找性、可访问性、互操作性和可重用性)原则。本文还简要概述了大数据、数据挖掘、自然语言处理及其相关学科领域的一些潜在应用,并特别关注本次 Omicron 浪潮期间的在线学习,可以通过使用此技术进行研究、探索和调查。数据集。
不断扩大的宇宙文明中交流的因果限制
原文标题: A causal limit to communication within an expanding cosmological civilization
地址: http://arxiv.org/abs/2208.07871
作者: S. Jay Olson
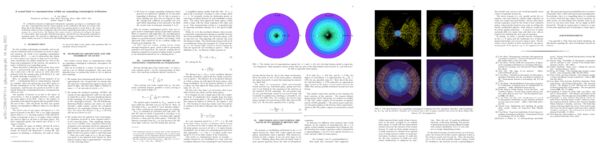
摘要: 如果一个文明开始高速星际扩张,随着时间的推移发展到宇宙学规模,由于距离太远,文明中遥远星系之间的通信将产生极大的时间延迟。事实上,如果净膨胀速度 v 超过 0.26c,由于因果视界的存在,这种文明的大部分最终体积将根本无法向母星系发出信号。我们根据与母星系可能的“对话”程度来说明这种文明的区域,并描述几何形状如何取决于膨胀速度。最后,我们反思了地平线以外的空间定居的价值,那里的殖民地永远无法被起始的母星系观察到。
声明:Arxiv文章摘要版权归论文原作者所有,机器翻译后由本人进行校正整理,未经同意请勿随意转载。本系列在微信公众号“网络科学研究速递”(微信号netsci)和个人博客 https://netsci.complexly.cn (提供RSS订阅)进行同步更新。个性化论文阅读与推荐请访问 https://arxiv.complexly.cn 平台。

作者:ComplexLY
微信公众号:netsci
欢迎扫描左侧微信公众号二维码进行交流!
本文地址:https://netsci.complexly.cn/post/20220817/